
Effortlessly integrate and
synchronize data from
3rd party sources.
Build real-time and batch
pipelines to transform data
using Python, SQL, and R.
Run, monitor, and orchestrate
thousands of pipelines without
losing sleep.
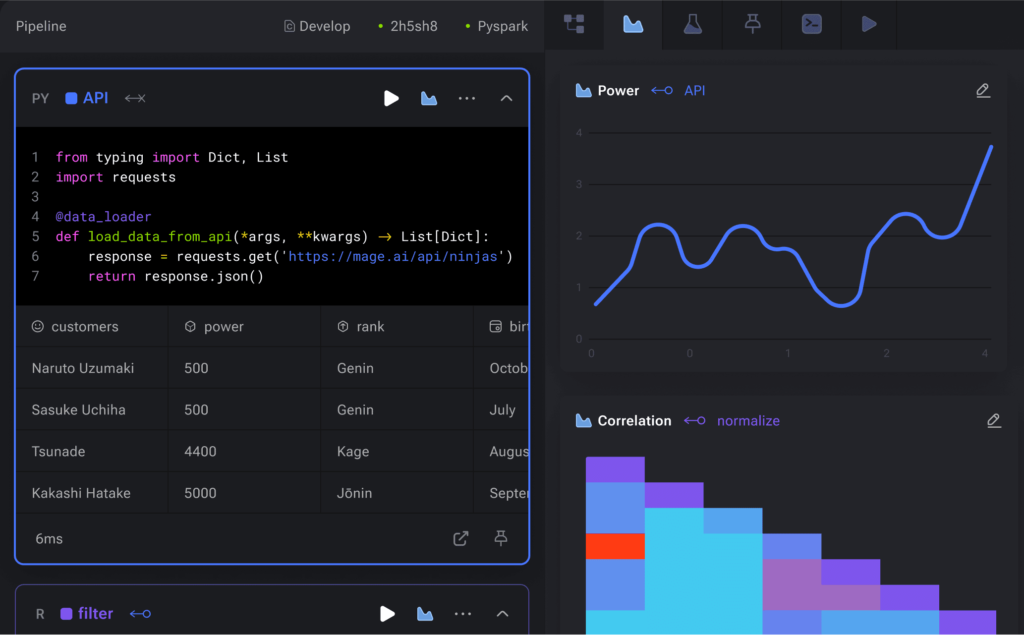
Start developing locally with a single command or launch a dev environment in your cloud using Terraform.

Write code in Python, SQL, or R in the same data pipeline for ultimate flexibility.

Each step in your pipeline is a standalone file containing modular code that’s reusable and testable with data validations. No more DAGs with spaghetti code.

Immediately see results from your code’s output with an interactive notebook UI.
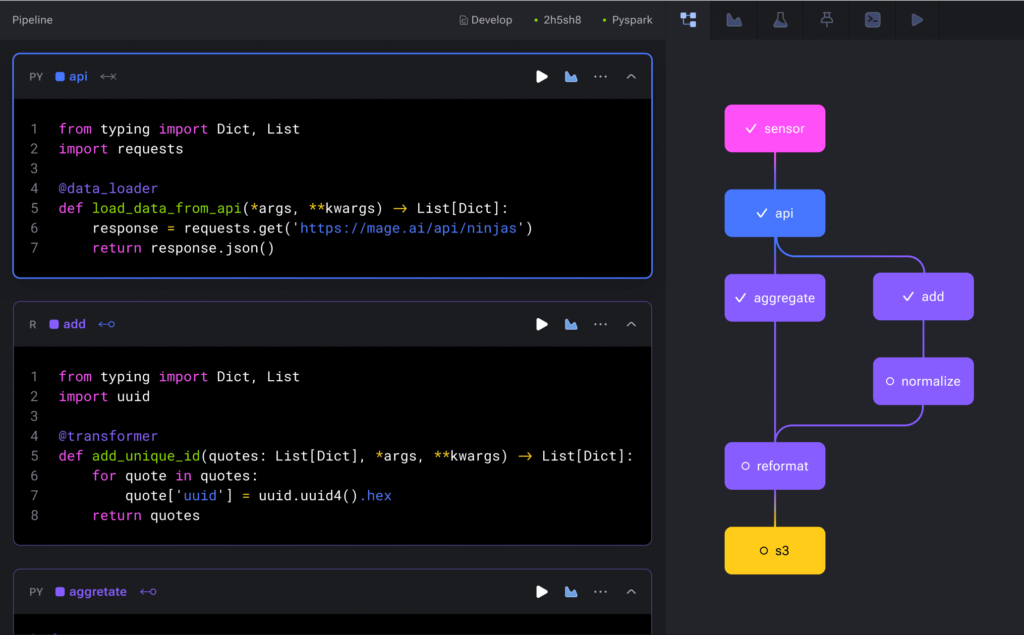
Each block of code in your pipeline produces data that can be versioned, partitioned, and catalogued for future use.

Develop collaboratively on cloud resources, version control with Git, and test pipelines without waiting for an available shared staging environment.

Deploy Mage to AWS, GCP, Azure, or DigitalOcean with only 2 commands using maintained Terraform templates.

Transform very large datasets directly in your data warehouse or through a native integration with Spark.
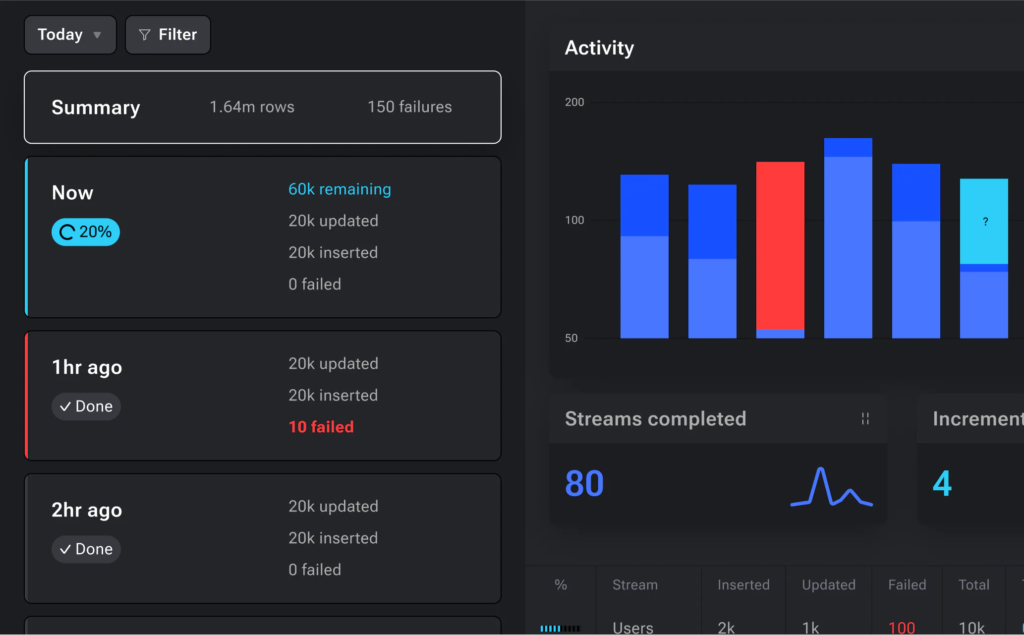
Operationalize your pipelines with built-in monitoring, alerting, and observability through an intuitive UI.


